再往下探究之前,我們輕鬆一點,先作點實驗,驗證上上篇的程式辨識準確率是否真的那麼高? 可否在應用系統上使用? 譬如,阿拉伯數字辨識率如果那麼高,我們是否可以提供手寫板,讓用戶直接輸入,用於輸入密碼、開鎖、填寫問卷、考試答題...等等。
另外,在實驗之前,我們先討論一些 Keras 小技巧,讓我們在開發程式時更有效率,包括:
模型訓練完畢後,結果如可接受,可以將模型存檔,下次要再測試時,就可直接載入,不需重新訓練,模型的資訊包括結構及訓練出來的權重(W)。
from keras.models import model_from_json
json_string = model.to_json() with open("model.config", "w") as text_file:
text_file.write(json_string)
model.save_weights("model.weight")
from keras.models import load_model
model.save('model.h5') # creates a HDF5 file 'model.h5'
之後,我們要使用時,可輸入下列程式碼,載入模型結構及權重(W)。
import numpy as np
from keras.models import Sequential
from keras.models import model_from_json
with open("model.config", "r") as text_file:
json_string = text_file.read()
model = Sequential()
model = model_from_json(json_string)
model.load_weights("model.weight", by_name=False)
或者直接載入HDF5檔案
from keras.models import load_model
# 刪除既有模型變數
del model
# 載入模型
model = load_model('my_model.h5')
f = np.load(get_file("mnist.npz", origin="~/.keras"))
x_train = f['x_train']
y_train = f['y_train']
x_test = f['x_test']
y_test = f['y_test']
f.close()
如果,直接從網路下載,可改為
f = np.load(get_file("mnist.npz", origin="https://s3.amazonaws.com/img-datasets/mnist.npz"))
Keras提供幾個事先訓練好的經典應用程式,不必重新訓練,可直接套用,請參考官方文件,使用方法如下:
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
model = VGG16(weights='imagenet', include_top=False)
官方文件找不到詳細用法,我花費好一番功夫才弄懂,後面談到 CNN 會詳細介紹,敬請期待。
Keras提供幾個現成的資料集,可作為訓練/測試資料,,請參考官方文件,包括手寫數字、分類圖片、影評、新聞、... 等。也可以自其他網站下載,例如,你覺得辨識0~9不過癮,也想辨識 A~Z, a~z,可至這裡下載。
我用C#寫了一個Draw.exe 小程式, Source Code 放在這裡,可以使用滑鼠,書寫數字,並將它存成與MNIST類似的格式(.csv),再用Python程式載入,依照訓練出來的模型測試是否可以辨識,步驟如下:
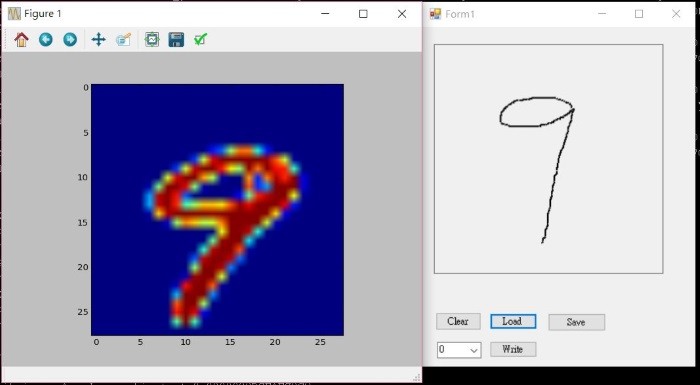
圖. 手寫數字 9 的比較,左為 MNIST, 右為筆者以 Draw.exe 手寫的數字
筆者反覆測試多次,發覺測試結果並不如MNIST測試資料那麼準確,正所謂『盡信書,不如無書』,原因如下:
另外,訓練出來的準確率均達85%,甚至95%,乍看很高,但仔細想想,如果是應用在銀行存款數目的辨識,使用者輸入10位數,只要一個數字錯,銀行老董可能就要崩潰了,反之,用在遊戲中,使用者可能會讚聲連連,驚嘆不已,所以,Machine Learning 的應用還是必須考量使用的時機與應用場域,才能贏得掌聲。
之前有試跑過MNIST數字辨識, 也是覺得它很厲害
感謝提供 Draw.exe
而我自己寫的數字, 用之前MNIST訓練出的模型, 辨識率不到一半..
試著找原因
可能是因轉成 28*28的圖,
轉換上有些失真,
比如我的0, 把它印出來, 就變這樣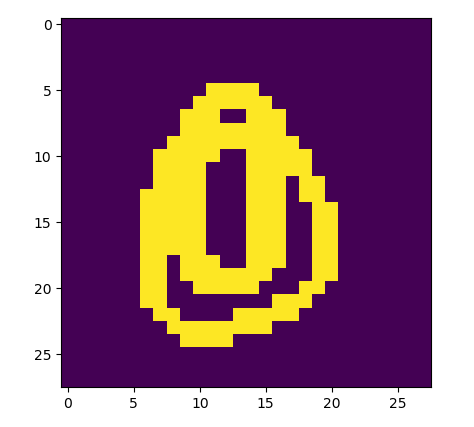
它就被辨識為 9 了
是,你說對了。
MNIST 的圖片應該是請測試者在紙上寫下來,再經掃描,所以,放大看如下,筆劃的寬度不固定且無鋸齒狀,與Draw.exe 不同,所以,辨識率較差。
請問老師要如何用Python程式載入CSV?試很久都沒辦法~
請問你是哪一班的同學?
我把程式放在 Google Drive,會保留三天。
請參考 0_1.py
for i in range(0, 10):
X2 = np.genfromtxt('./'+str(i)+'.csv', delimiter=',').astype('float32')
X1 = X2.reshape(1,28*28) / 255
predictions = model.predict_classes(X1)
# get prediction result
print(predictions)
C:\Users\pp>C:\Users\pp\Desktop\0_1\0_1.py
C:\Users\pp\Anaconda3\lib\site-packages\h5py_init_.py:36: FutureWarning: Conversion of the second argument of issubdtype from float to np.floating is deprecated. In future, it will be treated as np.float64 == np.dtype(float).type.
from ._conv import register_converters as _register_converters
Using TensorFlow backend.
Traceback (most recent call last):
File "C:\Users\pp\Desktop\0_1\0_1.py", line 14, in
X2 = np.genfromtxt('./'+str(i)+'.csv', delimiter=',').astype('float32')
File "C:\Users\pp\Anaconda3\lib\site-packages\numpy\lib\npyio.py", line 1689, in genfromtxt
fhd = iter(np.lib._datasource.open(fname, 'rt', encoding=encoding))
File "C:\Users\pp\Anaconda3\lib\site-packages\numpy\lib_datasource.py", line 260, in open
return ds.open(path, mode, encoding=encoding, newline=newline)
File "C:\Users\pp\Anaconda3\lib\site-packages\numpy\lib_datasource.py", line 616, in open
raise IOError("%s not found." % path)
OSError: ./0.csv not found.
抱歉,少放了0.csv,已補上。你可以使用 Google Drive 的 draw/draw.exe 寫 0~9,存檔後產生的.csv 放在 01.py 的相同目錄,再執行 01.py。
報告老師, 已解決問題, 實驗結果辨識度很不理想, 請問要多訓練嗎?
以下為實驗結果辨識度:
[5]
[1]
[2]
[3]
[9]
[9]
[6]
[7]
[5]
[9]
請參考本文的結論。
想請問一下我每次修改完超參數執行0.py後都會出現"GPU Sync fail"的訊息,然後就要重開機才可以執行,執行玩0.py後要執行01.py時卻又出現同樣的錯誤以致又要重開機,該怎麼做才不會發生這種一直需要重開機的情況
我沒有碰過這種情形,可以參考以下討論:
https://stackoverflow.com/questions/51112126/gpu-sync-failed-while-using-tensorflow
https://github.com/tensorflow/tensorflow/issues/1450
https://github.com/tensorflow/tensorflow/issues/4425
綜合來看,應該是 Cuda/cuDNN 安裝或是特定GPU的問題,例如 GTX 950M。



